Hystrix
Hystrix란?
MSA 분산 시스템인 Spring Cloud에서는 개발자가 분산 시스템에서 사용하는 공통 패턴을 제공한다. 예를 들면 Routing, Circuit Breakers, Routing, Configuration Management 등이 있는데 이 중 Hystrix는 Circuit Breaker 역할을 한다. 물론 Hystrix는 현재 Spring Cloud에서 fade out 되어 Resilience4j 사용을 권고하고 있지만 현재 회사에서는 Hystrix를 사용하고 있기 때문에 Hystrix 부터 정리해본다. Resilience4j도 비슷하겠지..?
예를 들어, 쇼핑몰을 MSA와 같이 분산 환경을 구성하다가 다음과 같은 도메인이 있다고 생각해보자.

어떤 회원이 주문내역을 확인할 수 있는 페이지에 접속했다. 이 때 보여주어야 하는 회원의 정보에는 상품에 대한 정보, 결제 내역에 대한 정보, 주문한 상품에 대한 배송 상태에 대한 정보가 나와야 한다고 가정해보자.
이 때 MSA 환경으로 구성되어 있다면 Member 도메인에서 Payment, Shop, Delevery 도메인으로 각각 api를 호출하고 정보를 모아 사용자에게 뿌려준다.
그런데 만약 이 때 특정 택배 회사 서비스에 문제가 있어서 배송 정보를 가져오는데 실패하거나 지연이 있다면? 이때 회원이 조회하려던 주문 내역 페이지 전체가 실패하거나 지연이 발생하면 큰 장애로 이어질 수 있다. 이런 경우를 방지하기 위해 있는 것이 Circuit Breaker다.
분산 시스템에는 다양한 이유로 일부 서비스가 실패할 수 있다. 외부 서버에 연결을 실패했다거나, 메모리 릭으로 서버가 죽거나, 일부 서버에 장애나 에러가 있거나 등등.
Hystrix는 이런 다양한 장애상황에 대해 견딜 수 있도록 아래와 같은 기능을 제공한다.
- 타사 클라이언트 라이브러리를 통해 엑세스되는 종속적으로 인한 지연 및 장애로부터 보호하고 제어
- 분산 시스템의 복잡한 연쇄 실패를 방지
- 빠르게 실패하고 빠르게 복구
- 가능한 경우 Fallback하고 Gracefully하게 종료
- 실시간에 가까운 모니터링과 경고 및 운영 제어
복잡한 분산 아키텍처에서는 수 십개의 종속성이 있고 이 종속성 중 일부는 어느시점에 실패할 수 있다. 만약 이런 api들이 외부 장애로부터 격리되지 않는다면 함께 중단될 위험이 있다. 실패보다 더 나쁜 것은 이런 서비스에 지연이 발생하여 대기열, 쓰레드 및 기타 시스템 리소스에 영향을 미쳐 시스템 전체에 더 많은 연쇄 실패를 발생시킬 수 있다는 점이다.
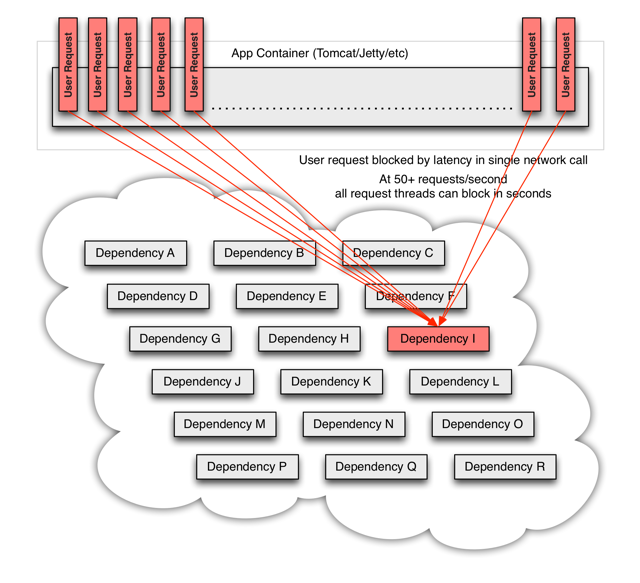
위 예시를 그대로 사용해 특정 배송회사 정보를 가져오는 api인 Dependency I에서 latency가 발생했다고 가정하자. 그러나 다른 회원들도 똑같이 주문 내역 페이지에 대한 정보를 지속적으로 요청하고 있다. 이 때 Client의 요청을 끊지 못하고 쌓다가 thread pool보다 많은 양의 요청이 축적되고, thread pool에서 처리되지 못한 많은 패킷들이 대기하며 지연되는 요청들이 점점 늘어난다. 이렇게 되다가 회원 서비스 자체에 문제가 생길 수 있으니 매우 위험하다.
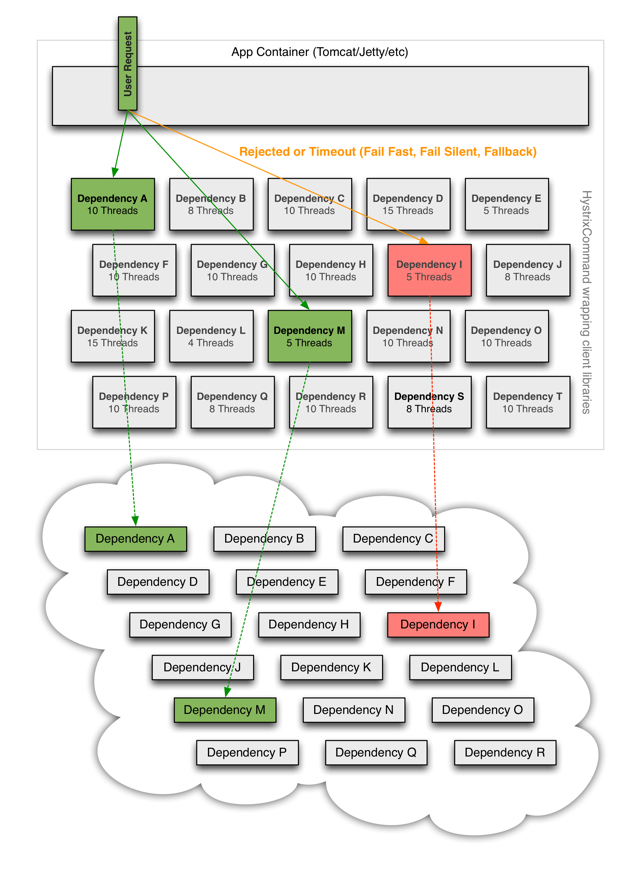
그렇다면 위 예시와 같이 회원의 전체 주문 리스트를 가져올 때, 특정 택배 회사의 배송 내역을 가져오는데 지연이 발생한다면 어떻게 해야할까? 우선 Hystrix에서 문제를 방지하기 위해 취하는 방법은 위와 같다.
- Container(Tomcat 등)의 thread를 직접 사용하지 못하게 한다.
- Queue로 대기열을 사용하지 않고 빠르게 실패하게 한다.
- 실패로부터 서비스를 보호하기 위해 fallback을 제공한다.
- circuite-bracker나 격리 기술을 이용하여 외부 장애의 영향을 최소화한다.
- 실시간에 가까운 모니터링 및 경고 시스템을 통해 실시간 운영 수정을 수행할 수 있게 한다.
- 네트워크 뿐만 아니라 전체 종속성 client 실행의 장애로부터 보호한다.
Hystrix 동작 방식
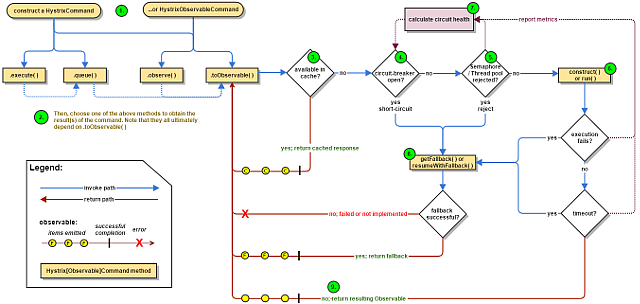
- HystrixCommand 나 HystrixObservableCommand 객체 생성
- Command 실행
- Response 캐시 여부 확인
- Circuit이 열려 있는지 확인
- Thread Pool / Queue / Semaphore이 꽉 차있는가 확인
- 실제 명령어(function) 호출
- Circuit Health 확인
- Fallback 호출
- 성공 Response 반환
즉, 6번 실제 명령어를 실행하기 전에 캐싱 -> circuit -> thread pool / queue / semaphore (hystrix에 설정한 값에 따라 다름)를 확인한다.
circuit을 열고 단는 것은 일정 시간 동안 일정 요청 이상의 실패율을 가질 때 열고 닫고 지정해둔 시간이 지난 후 로직에 대한 성공 여부에 따라 다시 닫을 지 판단한다.
Isolation 전략
Hystrix는 main thread와 호출되어지는 thread를 고립시키기 위해 thread 방식과 semaphore 방식 두 가지 중 하나를 선택할 수 있다.
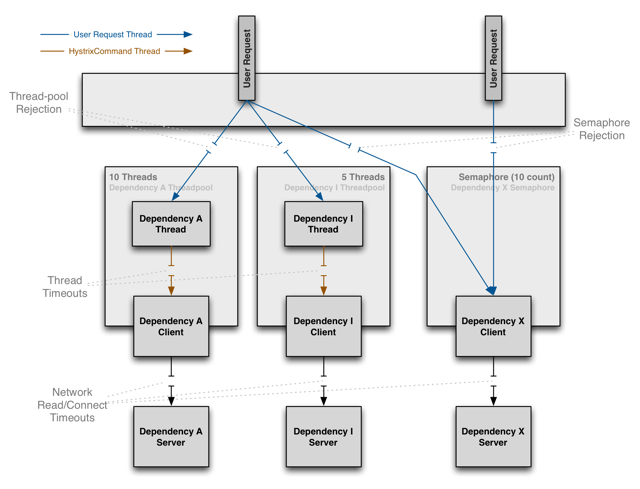
왼쪽 2가지는 thread 방식이고, 오른쪽은 semaphore 방식이다.
Thread 방식
main thread와는 별도의 thread-pool을 구성해서 thread-pool을 자원으로 이용하여 사용하는 방식이다.
thread pool을 사용했을 때의 장점
- hystrix에 감싸져 있는 외부 시스템을 호출하는 부분을 완전히 main과 격리할 수 있다. 이렇게 thread-pool을 격리하면 main thread pool에는 영향을 주지 않을 수 있다.
- 새로운 dependency를 추가할 때의 리스크를 최소화할 수 있다.
- 실패한 원격 서버가 정상 상태가 되면 전체 tomcat의 thread를 점유하고 있을 때보다 thread pool 을 사용했을 때가 즉각적인 성능회복이 더 빠르다.
단, thread 방식은 잦은 context switching이 일어나서 전체적인 성능에 영향을 줄 수 있고 빠르기는 semaphore가 더 빠르다고 한다.
Semaphore 방식
별도의 thread pool을 생성하는 것이 아니라 main thread-pool에서 할당받아 사용하는 방법
thread 방식에 비해 속도와 성능은 좋지만 격리성은 thread 보다 낮다. (netflix에서는 thread 방식을 권장함.)
참고자료
'개발' 카테고리의 다른 글
| [Cloud] Docker란? (Docker의 개념과 기본 사용법) (0) | 2022.03.31 |
|---|---|
| [Redis] Redis 설치(docker)와 redis-cli 사용법 (0) | 2022.03.29 |
| [Golang] Go 언어 빠르게 훑어보기 (0) | 2021.10.26 |
| gradle (0) | 2021.08.16 |
| WSL(Windows Subsystem for Linux)이란? (0) | 2021.05.23 |